With the growth of IoT and connected devices, companies can capture and store more and more data. Recording is however only part of the deal. Data needs to be analysed, packaged, and utilised in order to be useful and, as a consequence, valuable. But what is the right package? How does one capture the most of it?
During a talk at the Cambridge Innovation Centre (CIC) in Rotterdam, Daniel Faloppa, co-founder of Equidam, shared how he sees these issues, what does actually make data valuable, and a framework for positioning and packaging data as a product.
His experience comes from his 5 years at Equidam, the market leader in online business valuation, that accumulated vast knowledge in both estimating the valuations of data companies as well as making the best use of vast amounts of data for the calculation of valuations themselves. So where does the value of data come from?
The value of data is in the cash flows it generates
If data doesn’t contribute to the cash flow of a company, it can be irrelevant and just an additional cost. The data generates cash flows (and becomes valuable) in three ways:
- Increasing revenues
- Reducing costs (read: increasing business efficiency)
- Creating barriers to entry (against competitors so protecting profit opportunities)
Dragged by the hype, companies are collecting more and more data, often without considering its implications and potential cost structure. Companies often happen to be unaware that they collect data of little or no value to their core business. It is therefore crucial to consider why data is collected and how to avoid the wasteful use of resources.
This process starts with considering the difference between collector of the data and beneficiary of the insights. These could be indeed two different entities and there are many situations in which they are.
The collector of data might not be its main beneficiary
In some cases the data collector is also the main beneficiary of the created insights. This is the case for companies like General Electric (GE), which collect their own data to optimise their supply chain, production, and general operations. In contrast to companies like GE, there are companies that collect data but do not directly benefit from them. When a third party can extract more value from the data than the collector, there is a transaction opportunity as the party that benefits is interested in purchasing this data.
The difference in values that the two companies attribute to their insights is the maximum price that this transaction can sustain. However, only part of the value can be captured by the seller through price. In this framework, the two variables are then the maximum value created and the percentage of the value captured.
Data generates value because of the insights it gives into solving a business problem. As a company selling or brokering data, you should always look at what problems the data solves.
The more you solve of a problem, the more value you can capture
So what is the maximum value that can be captured by a company? According to Daniel “the most value is created when a business problem is solved. The more of that problem your company solves, the more value it will be able to capture.”
Startups and entrepreneurs are really familiar with this concept. When you create a company, you do it to solve a pain point for your customers. If you do that, they will pay the company an amount that for them is lower than the pain having that problem. When dealing with businesses, the calculation of the “value of that pain” is much easier to determine, and it boils down to increased sales, reduced costs, increased growth etc…
Having that as the maximum value, a data company that acts as a service provider can capture a larger or a smaller share of that maximum value according to its product. The more the product is a fully-fledged solution, the more value is captured by the seller, since the amount of “pain” removed from the buyer is at its highest. The less the product provides a solution, the more the buyer needs to create the solution from it on its own, reducing the value he’s willing to transfer to the seller.
According to Daniel, the extreme cases are:
- providing raw data that leave figuring out of a solution to the buyer
- provide a fully fledged package that precisely solves that problem
By selling raw and unprocessed data, a company provides little to no solution as the analysis, actual insights, and processes to solve the problem are left to the buyer. Enterprises receiving raw data therefore have to employ analysts, project managers, and specialists to solve the problem on their own.
An example of raw data selling is Quandl.com. Quandl created a platform for financial, economic and alternative data that serves investment professionals. Their scope of business boils down to data collection and structuring, adding value with ease of use and extraction but with no further analysis or insights. This allows them to capture only a little percentage of the value created by their insights. So why would they do it?
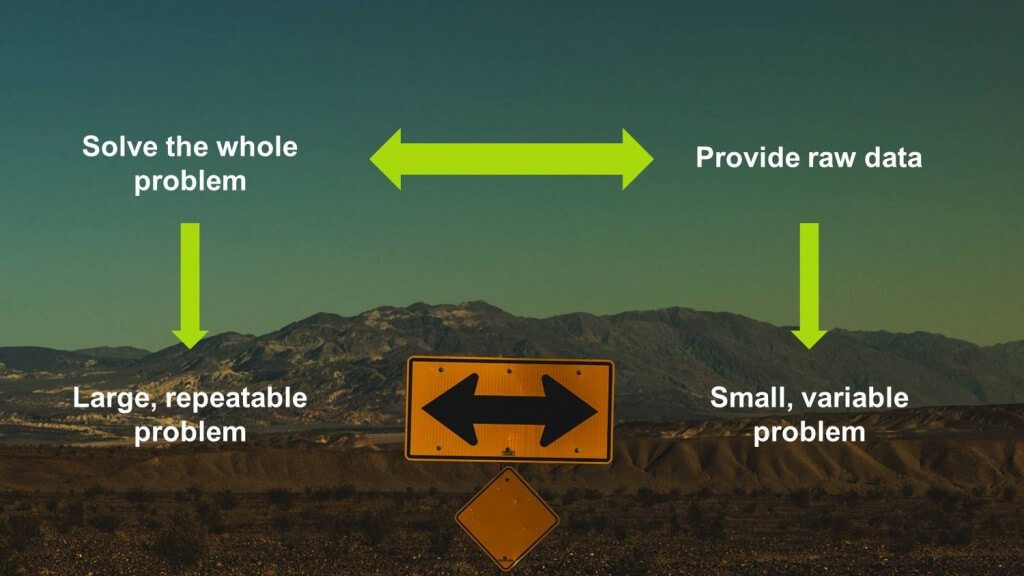
A useful framework to think about this is to look at the scale and variability of the problem data can solve.
Indeed, the more widespread and valuable a problem is, the more it is worthy to provide a full solution. On the other hand, a small and highly variable problem should be approached with providing raw data and let the specific buyer solve the specific problem.
When providing a solution, a company indeed creates economies of scale. It learns how to solve that problem better than anybody else, it makes its processes cheaper and more specialised and, ultimately, it creates competitive advantages with respect to solving that problem. The smaller and more variable the problem is, the harder it is to have specific knowledge, simply because there are too many cases.
From this reasoning, the natural conclusion is then to solve as much of the problem as possible, without overspecialising on too-small, too-variable problems.
To explain this issue we can take Palantir, a software company specialised in big data analysis. Palantir created a sophisticated technology for big data analysis that is offered to several verticals. Providing the technology alone would, however, solve the problem for the customer (analysing large quantities of data) only partially. Clients would still have to figure out the data, how does it work with their own systems, how to configure the most important analyses etc. So instead of providing online or on-premise technology, Palantir positioned itself as the full-solution seller, customising the technology to each client, sending engineers on premise to figure out the best applications, developing part of the analyses etc. With this, it is then able to capture the maximum value of this data processing technology.
But how to figure out variability and size of the market? According to Daniel, the only way is “to keep analyzing the size of the problem you can solve and continuously listen to your customers “.
In conclusion, the data collection is not enough. Companies should carefully assess the value of the data they collect and the analysis they can perform on it. Raw data is often of a little interest and low value as it is only a small part of the solution to a problem. In Daniel’s words
“the future is not going to be defined by companies that have the most data but by companies that extract the most value from it”.